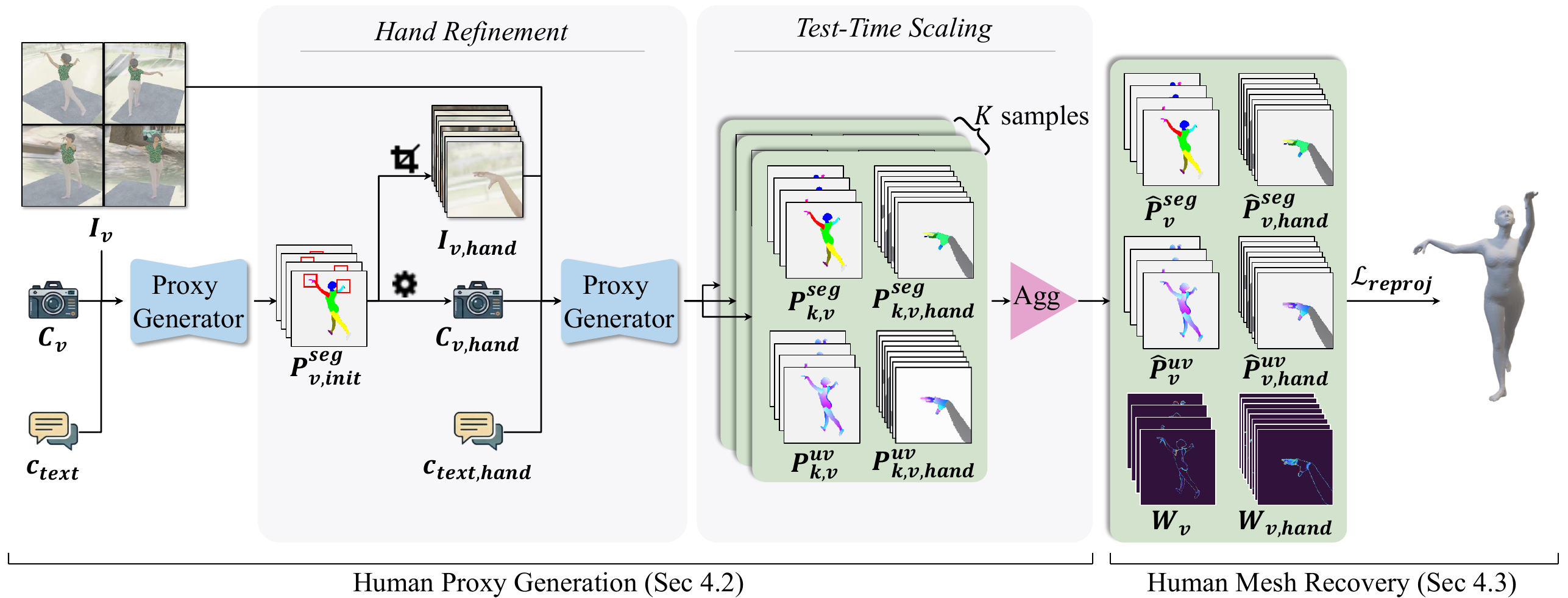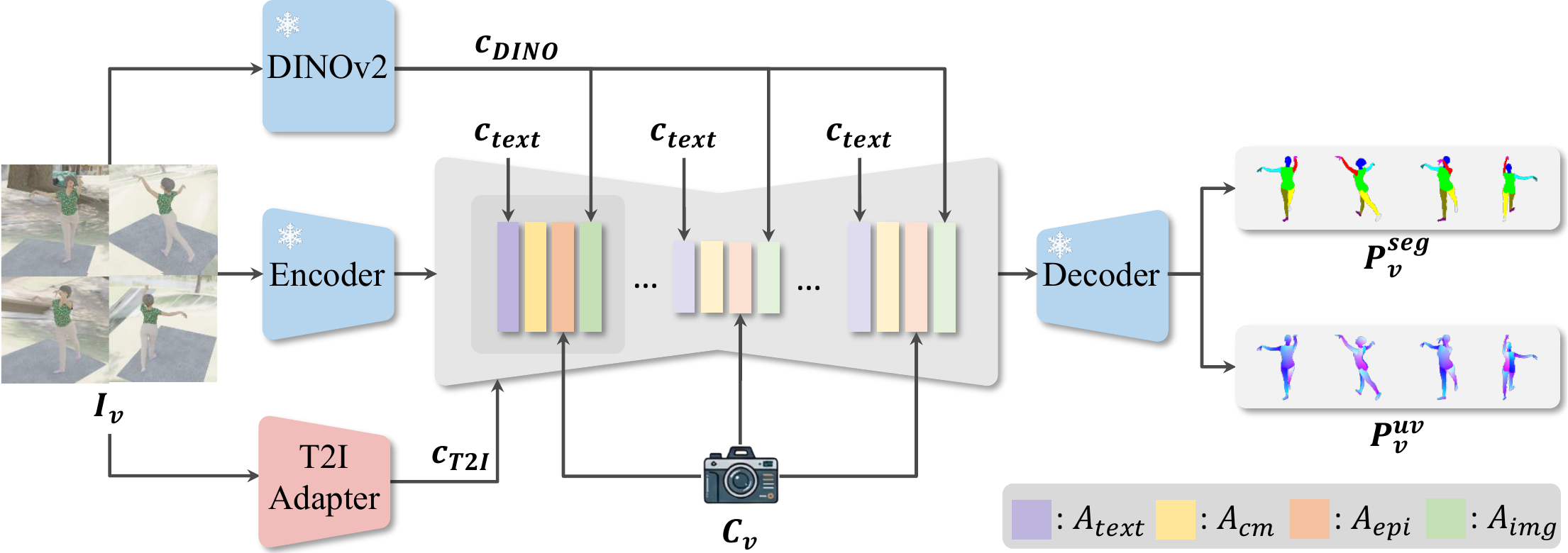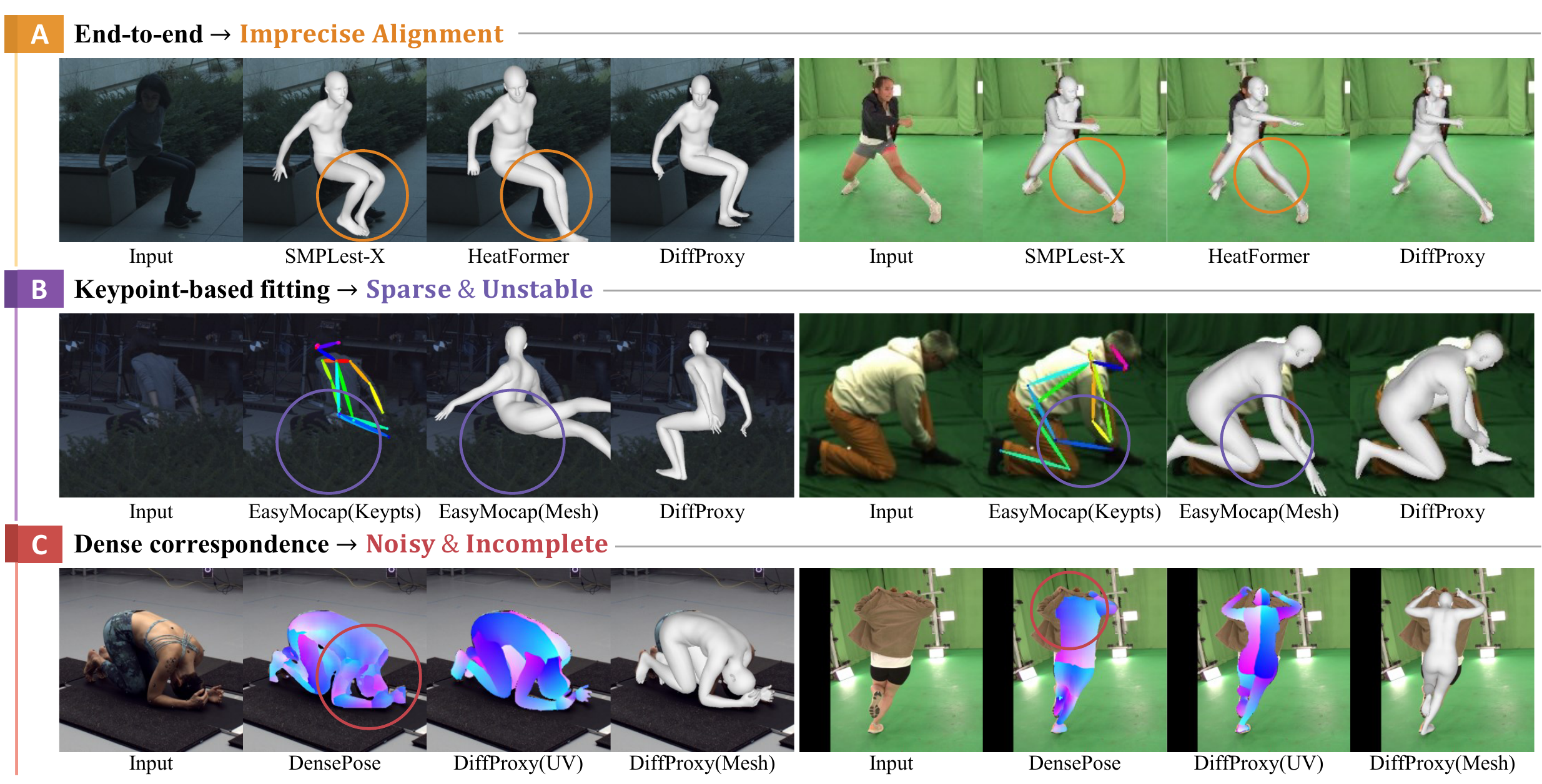
Existing human mesh recovery methods face distinct challenges. (A) End-to-end methods (SMPLest-X, HeatFormer) produce imprecise image-mesh alignment; (B) keypoint-based fitting (EasyMoCap) is sparse and unstable under challenging conditions; (C) prior dense correspondence predictors (DensePose) produce noisy and incomplete surface mappings. We introduce DiffProxy, which uses a diffusion model trained on synthetic data to predict accurate dense pixel-to-surface proxies, then fits SMPL-X against them via a unified reprojection objective, achieving precise alignment across diverse real-world scenarios.